Space Allocator
Here, I will try to make a allocator. I'm doing this for my bff project. The mentioned project uses a file to store several objects. These objects can be modified or deleted. Also, new objects can be created in the file. Each object can be spread over multiple blocks if necessary, but this should be avoided as much as possible. Objects can be of any size, and there can be many small objects. This pretty much rules out using fixed sized chunks as the space wasted can be significant. The aim of this algorithm is to- reduce the number of blocks per object
- avoid seeking backwards when reading an object
- keep the file size small by reusing deallocated areas
Let's talk about what I should do when an object is destroyed. There are two scenarios:
Scenario 1: object A is destroyed object B is created file is written out Scenario 2: object A is destroyed file is written outIn scenario 1, any work done related to the deletion of A would probably be overwritten by the second action. It might be better to delay deallocation actions because of this. Actually, it's better to delay ALL actions as much as possible (constrained by memory). Consider the case where there are a bunch of intermingled creation/destruction requests. I could work out the best way of satisfying the requests by looking at the pool of requests and assigning space to new objects from the deleted objects.
Then, scenario 2 should also be handled as if it was scenario 1. If a big object gets deleted in the middle of the file, then a lot of work needs to be done to get rid of that space. That might not be very nice to the end user. Just consider yourself waiting for your tablet trying to shutdown the program when all you did was delete a uselessly big item from a document. Not pleasant. However, the same waiting time would be considered reasonable if you did a bunch of modifications.
In any case, if the user destroys an object, we make a record of it in memory and write out the fact at file close if the space is still free.
Scheduler: Trivial Rules
I'm going to need a way to represent actions so that they can be stored in a buffer until some memory criteria is met. Luckily, the library I'm targeting already allocates user-invisible buffers to write the stuff out. Therefore, this process can be invisible to the user.There are a couple of things which I need to write down. These are trivial, but need to be coded anyways.
SCHED-01: If DEL(A) follows CREAT(A), then both actions can be ignored.
SCHED-02: If WRITE(A) follows CREAT(A), then the creation action can be
ignored.
SCHED-03: If WRITE(A) follows WRITE(A), then the prior action can be
ignored.
SCHED-04: if DEL(A) follows WRITE(A), then the prior action can be
ignored.
Since objects are no longer immediately valid on disk, the
code which reads objects also needs to consider the scheduler cache.
OK, now let's try to solve the real problem: We've hit the scheduler cache limit and there is a bunch of CREAT/WRITE/DEL actions on our hands.
First Attempt
First of all, we should split up write actions into DEL/CREAT pairs. Since objects are written whole, there is no point in keeping an object at a specific point in the file. Now, we have a bunch of DEL/CREAT requests.The deletions should be done first in order to make space for the new objects. In the previous section, I had decided to do no work for deletion requests. These simply mark the associated areas as free. The only real work gets done during object creation.
My first algorithm is the following:
- Deallocate any object as soon as requested.
- When an object is created:
- Look at the biggest free block, if the object fits there, use it.
- If it doesn't fit, get the second biggest free block as well. If the object fits into these two, use them.
- Otherwise, put some of the object data into the biggest free block, completely filling it. Put the rest at the end of the file.
- If there are no free blocks at all, just put the stuff at the end of the file.
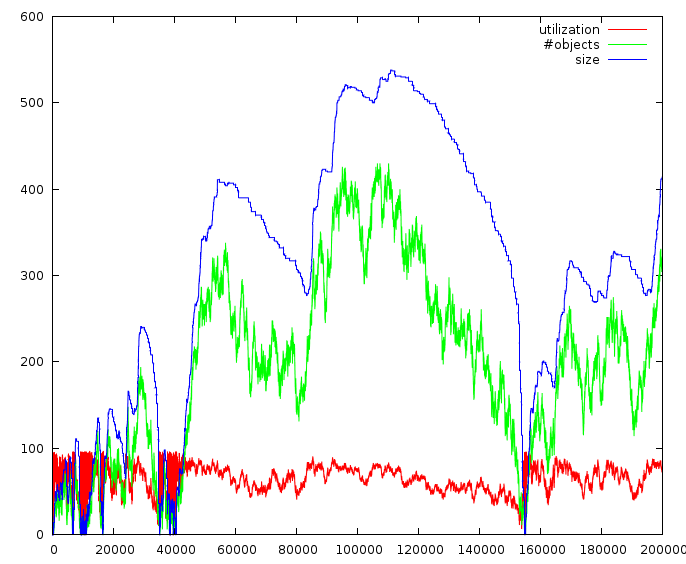
I did 2e5 randomly chosen operations. Each operation is either an object creation or deletion. The step number is the X axis.
The file size (in kilobytes) seems to be following number of objects quite closely. I did different runs with different maximum object sizes, but I get similar results every time. In this graph, maximum object size is 2048. When I increase it, the size graph gets elongated in the Y axis but still follows the shape of the number-of-objects line.
The utilization factor seems to be swinging between 40% and 90% most of the time, reaching as low as 0%. However, this happens only when the number of objects is small. When that is the case, the file size is already quite small so I think I can disregard those.
It's best to keep in mind that this workload is totally random and some real world workload could end up staying always in the lower part of the utilization scale. For now, I'm going to go ahead with this algorithm. When I implement the applications I'm thinking of, maybe I can store some statistics to decide whether I should improve.
I also didn't implement the cache or the scheduler. I'll see about that later.